









































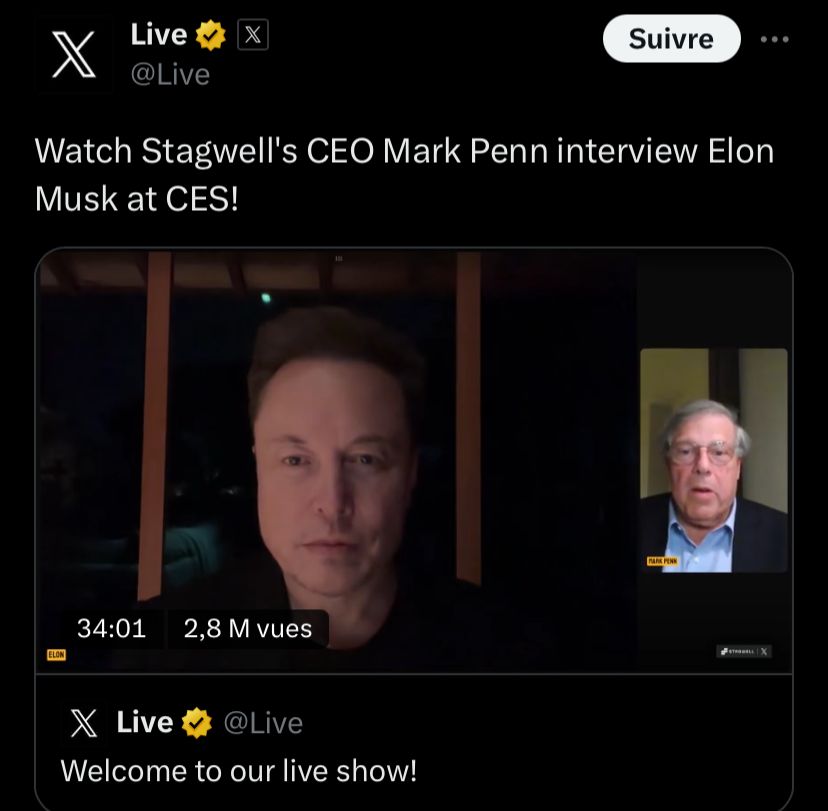
Dans un entretien diffusé hier en direct sur sa plateforme X (anciennement Twitter), Elon Musk a abordé un sujet préoccupant : la pénurie de données nécessaires à l’entraînement des intelligences artificielles. Lors de cette conversation avec Mark Penn, président-directeur général de Stagwell, Musk a affirmé que l’intégralité des connaissances humaines avait été épuisée pour former les modèles d’IA, un constat alarmant qu’il a qualifié de réalité survenue l’année dernière.
Musk a souligné que cette pénurie de données constitue l’une des principales faiblesses des grands modèles de langage actuels. Pour pallier ce manque, il a proposé l’utilisation de données synthétiques, une approche qui, bien que prometteuse, n’est pas sans risques. En effet, l’entraînement des IA sur des données générées par d’autres intelligences artificielles pourrait entraîner des « hallucinations », c’est-à-dire des erreurs dans les réponses fournies par ces systèmes.
L’utilisation de données synthétiques n’est pas une nouveauté. Elle permet non seulement de surmonter la pénurie de données, mais aussi de réduire considérablement les coûts d’entraînement. Par exemple, la startup Writer a réussi à diminuer le coût d’entraînement de son modèle Palmyra X 004 à 700 000 dollars, contre 4,6 millions de dollars sans l’utilisation de données synthétiques. Des géants comme Microsoft et Google ont également intégré cette méthode dans leurs modèles, tels que Phi-4 et Gemma.
Cependant, Musk met en garde contre le risque d’un « effondrement de modèle », un phénomène où une IA, entraînée sur des données erronées produites par une autre IA, pourrait perdre en créativité et augmenter les biais. Ce risque pourrait contraindre les entreprises à repenser la conception de leurs modèles d’IA pour éviter de telles dérives.
Alors que l’IA continue de progresser, la question de la qualité et de la provenance des données d’entraînement devient cruciale. Les solutions synthétiques pourraient offrir une voie à suivre, mais elles nécessitent une évaluation rigoureuse pour garantir la fiabilité et l’intégrité des systèmes d’intelligence artificielle.


